






KEYWORDS: #face parsing #human segmentation #videoface #ai face video #open datasets #segmentation datasets
Nowadays, face parsing has already become part of our life.
Facial recognition is a well-known technology that belongs to facial parsing. It is used for account login, unlocking, and anti-theft systems.
Also, in fields like entertainment, social media and medical beauty, face parsing has more extensive and diverse potential.
After reading this article, you will know:
- What is face parsing?
- Application scenarios of face parsing.
- How does face parsing work?
- The related open and commercial datasets.

What is face parsing?
Face parsing, known as face analyses, is an important computer vision task that requires accurate pixel segmentation of facial parts (such as eyes, nose, mouth, etc.), providing a basis for further face analysis, modification, and other applications(1).
Application scenarios of face parsing
Now let’s move to daily scenarios to understand face parsing. You will be surprised how wildly and diversely this technology has become part of our day-to-day life.
Security Industry
Face parsing is mainly used to identify identities.
For example, we prevent unidentified or blocklisted people from entering the premises and finding missing people. We also use it for warehouses and factories safeguarding, residential intelligent security systems and identify.

Medical beauty industry
Face parsing in medical beauty can help customers to analyze the best and most appropriate facial adjustment plan before the operation. It can also help the patients to evaluate surgical results.
Social media industry
For instance, we often use facial beauty effects for photos, videos and online meetings. Face parsing helps us to achieve more desirable results.
Let’s say we expect more vivid rouge lips with fairer skin. Different facial features need different beautification strategies. Otherwise, we might receive a horrible-look photo.
I believe no one would like to post this kind of photo on social media platforms unless it’s Halloween.

Entertainment industry
It is common to add earrings, sunglasses, and other unique decorative effects to our faces via Mobile apps. We can even use Apps to change our faces to someone else.
In this case, face parsing has done a marvelous job.
First, analyze users’ faces, then put on the ornaments in the correct face position. Scaling the same semantic features of the target graph and the source graph to the same size, then switching.
Autonomous vehicle industry
It includes Identifying drivers’ status for safety purposes, protecting the property security of the vehicle as well as payment security.
Autonomous vehicles can use face recognition technology to store drivers’ behavioral preferences, historical trajectories, etc.

How does face parsing work?
Representative network structure is FCN, which is Fully Convolutional network. Its model structure is very simple. For example, VGG is used to extract image features, remove the last full connection layer, use Transpose Convolution of up-sampling to restore feature images of multiple down-sampling to the same size as the original image, and then generate a classified label for each pixel.
Generally, The CNN network will connect the full connection layer after the convolutional layer and map the feature map generated by the convolutional layer into a feature vector of fixed length.
However, FCN needs to classify pixels and accept input images of any size. FCN uses deconvolution to upsample the feature map of the last convolutional layer to restore it to the same size of the input image, thus generating a prediction for each pixel while retaining the spatial information in the original input image.
Finally, pixel-by-pixel classification is performed on the feature map of upsampling.
Face recognition, as core and wildly-used technology, deserves a more specific explanation.
Technically speaking, face recognition needs to obtain face key points first, then extract feature codes through key points to calculate the Euclidean distance between the face codes in the database and the visitor’s face codes, and complete face recognition.
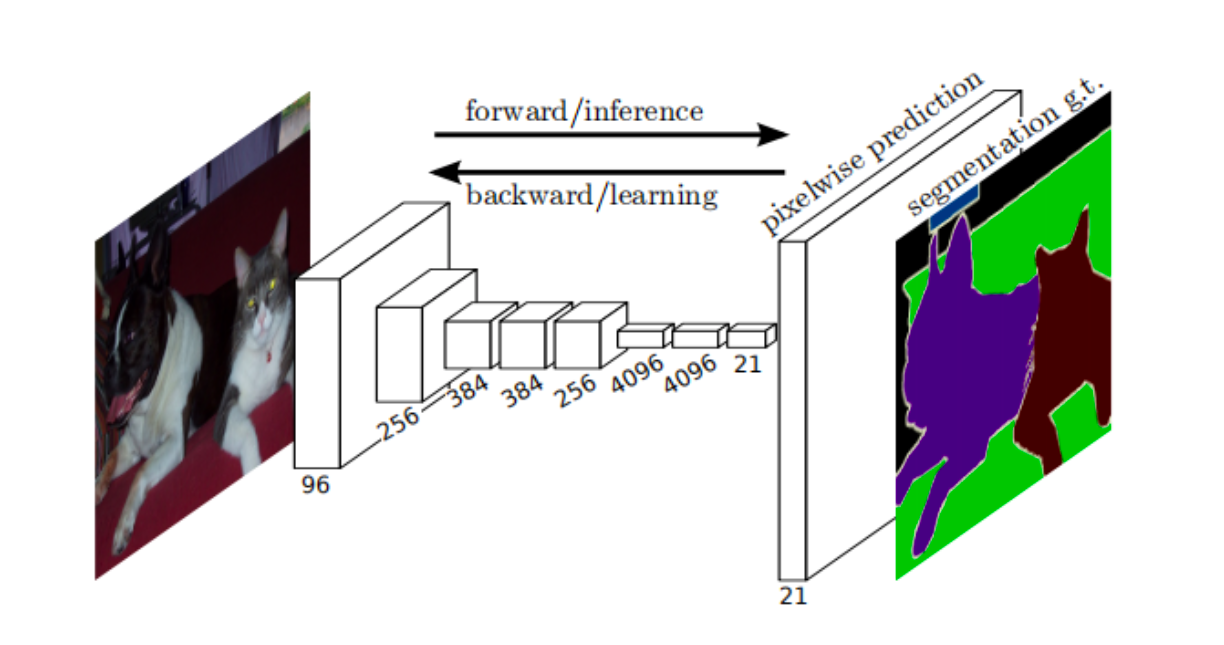
There are two ways to obtain face key points:
1. Directly regressing several key point coordinates by the model.
2. According to semantic segmentation technology, the continuous pixels after segmentation are thinned to obtain the key points.

The related open and commercial datasets.
Open datasets
1. Lapa(landmark guided face parsing dataset)
The Lapa1 dataset contains a total of 2.2W images, including 18176 images as a training dataset and 2000 images as a test dataset. There are 11 semantic categories, including 106 personal face key points. The Lapa dataset generates semantic segmentation graphs guided by dense face key points.

more Infos: https://github.com/JDAI-CV/lapa-dataset
2. CelebAMaskHQ2
The dataset contains 30,000 images of faces. The training dataset was 24183, and the test dataset was 2824. A total of 19-pixel categories are marked for the face content and for some accessories such as glasses, earrings, and necklaces. The annotated images of the dataset came from CelebA, and the resolution of the images was 512×512.
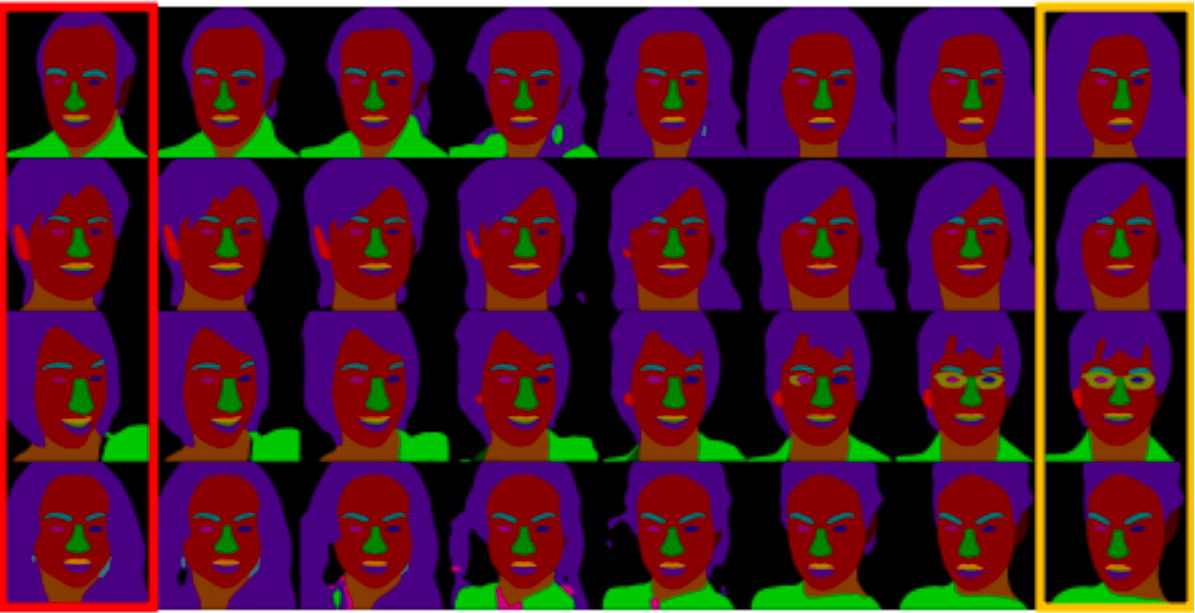
3. iBugMask3
The dataset contains 21866 training datasets and 1000 test datasets. The training data is enhanced according to the existing data set,and the training data of large posture is obtained by rtating the face of the figure at a certain Angle.

4. Hellen4
A total of 2330 images are included, 2000 as training data, 230 as Val dataset and 100 as test dataset. However, there are some labeling errors in face and hair categories, because some labeling is automatically generated by algorithms.
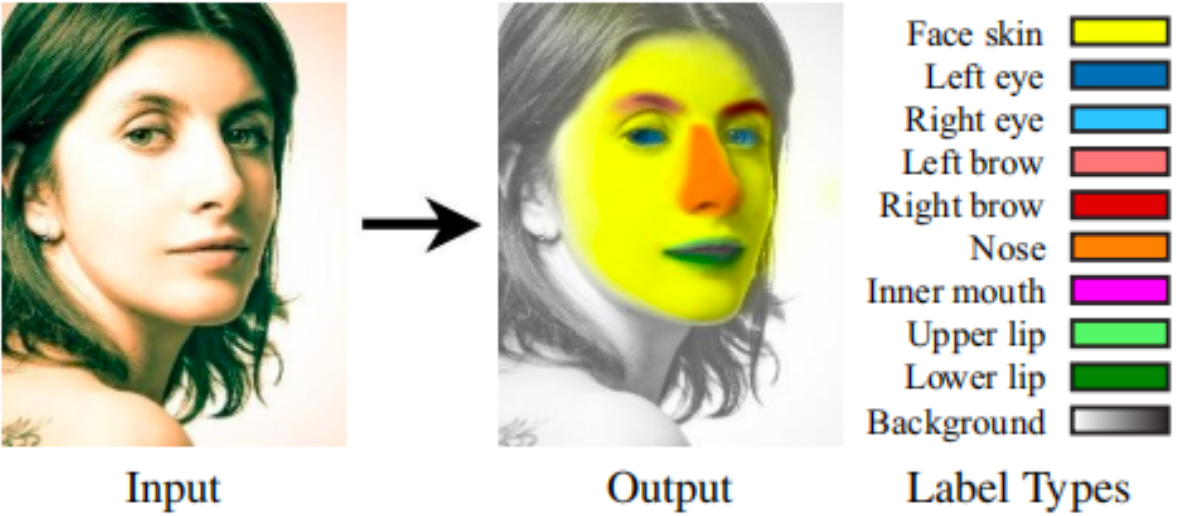
Commercial datasets
Maadaa’s available immediately commercial datasets are listed below:
1. Face parsing Dataset:MD-Image-006
MD-image-006 is a semantic segmentation dataset of faces collected from the Internet and evenly distributed by gender and age. There are 10W labeled images in the dataset, and the pixel category contains 18 facial features.

more Infos: https://maadaa.ai/dataset/face-parsing-dataset/
2. Indoor Facial 182 Keypoints Dataset: MD-Image-012
Total 50 persons in an indoor scenario, with balanced gender, age from 18 to 50, 182 key points, around 28000 images.

more Infos: https://maadaa.ai/dataset/facial-182-keypoints-dataset/
3. Indoor Facial 75 Expressions Dataset: MD-Image-011
Total 60 persons in an indoor scenario, with balanced gender and variable postures, 75 facial expressions per person, about 20k photos, with facial expression category tags.

more Infos: https://maadaa.ai/dataset/facial-75-expressions-dataset/
4. Facial Parts Semantic Segmentation Dataset: MD-Image-019
Face area categories include skin, left eye, right eye, left eyebrow, right eyebrow, nose, left ear, right ear, mouth, upper lip, lower lip, hair, cap, glasses, wearing accessories, neck, clothing, etc.
About 2,791.7k Images were collected online and offline, with resolutions ranging from 300 x 300 to 4480 x 6720.

more Infos: https://maadaa.ai/dataset/facial-parts-semantic-segmentation/
Reference List:
Yin, Z., Yiu, V., Hu, X., & Tang, L. (2020, June 23). End-to-end face parsing via interlinked convolutional neural networks. arXiv.org. Retrieved August 25, 2022, from https://arxiv.org/abs/2002.04831v2
