





KEYWORDS: GPT-4, diffusion models, ChatGPT, OpenAI, text-to-image, text-to-video, text-to-x, DALL·E
Although the ChatGPT craze seems to be slowly fading, many industry insiders believe that a new singularity in the development of AI-based technology has arrived.
Let’s take a step back in time to 2022, from the AI painting trend caused by Disco Diffusion and DALL·E 2 in May to chatGPT in November, countless AIGC products and startups have emerged during this period, which together have created a boom in AI creation.

From text-to-text, represented by ChatGPT, to text-to-image, coding, video, speech, etc. More and more information proves that multimodal models are getting closer to us.
There is a rumor that GPT-4 will be multimodal: that is, it will be able to work with images, video and other data modalities in addition to text.
Although there was no official response from openAI, CEO Sam Altman did mention some interesting thoughts in a podcast interview, AI for the Next Era.
Altman said:
“I think we’ll get multimodal models is not that much longer, and that’ll open up new things.
…I think we will get true multimodal models working.
And so not just text and images but every modality you have in one model is able to easily fluidly move between things.” [1]
Therefore, before we officially meet multimodal models, based on diffusion modes, Text-to-X will be full of infinite possibilities.
1. Text-to-Image
What happened:
In early February 2022, Disco Diffusion appeared as an AI image-generating program that could render images based on keywords describing a scene. Its appearance was the beginning of a whole year of AI Art frenzy in 2022.
In April of the same year, DALL-E 2 was launched; in August, Stability Diffusion was launched and on 18 October, Stability AI successfully raised funding and became a unicorn company.
Behind the news:
In fact, when it comes to the underlying technology, diffusion models are a complete revolution for GAN.
Diffusion models are a type of generative model that can generate visual content from noise and can be controlled by other conditions such as text, prompts, and images.
In recent years, diffusion models have gained popularity in the computer vision due to their ability to generate diverse and high-quality visual content compared to other generative models such as GANs.
GANs are notorious for being difficult to train due to their promotional goal, and they often suffer from mode collapse. Diffusion models, on the other hand, have a more stable training process and provide more diversity because they are based on probability.
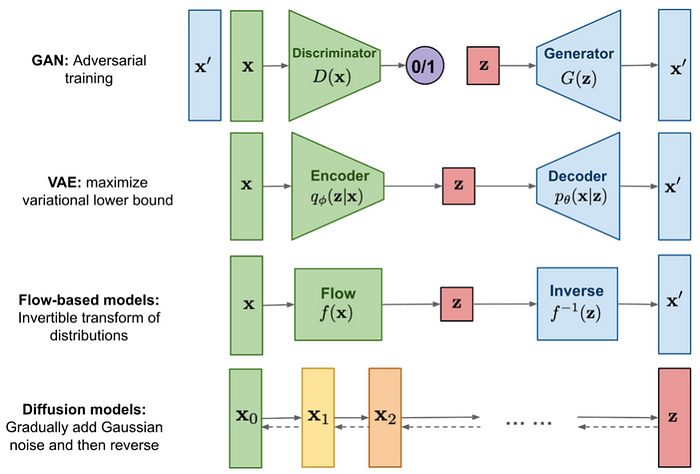
Difference between Diffusion Model and Other Generative Models
maadaa.ai predicts:
Because the technology is open source, the public’s enthusiasm for chasing it will continue. Speculators are able to enter the field at almost zero cost, which has led to a number of disruptions.
One type of player, in the case of Avatar AI, can make a quick buck by packaging 100 avatars for $12 or less, but how to maintain long-term business value without hurting the curious consumer is a question Avatar AI has to consider.
Also, a type of player that simply offers tools to users for free, but how to generate revenue to sustain further development after the initial viral growth?
However, we know that in order to generate content, people first need to go through a huge amount of high-quality data training, which inevitably leads to copyright disputes.
In fact, some text-to-image AI products have already infringed on artists’ copyrights. A class-action lawsuit alleges that the AI art generators Stability AI, Midjourney, and DreamUp were trained on billions of copyrighted materials without credit, compensation, or consent of content owners.[2]
But if we look on the bright side, the same argument exists for recognizing the artistic value of AI works, as seen in the decision to award ‘Théâtre D’opéra Spatial’ after it was an AI-generated work.

2. Text-to-Video
What happened:
If text-to-image generative AI is one of the biggest stories in AI in 2022, ‘text-to-video’ will undoubtedly take over as the new technology focus for 2023.
From futurepedia.io, the largest daily updated directory of AI applications, ChatGPT is in the first place, followed closely by Fliki, a text-to-video AI tool.
While producing the best videos will always require creativity and human sensitivity, artificial intelligence software can be used to reduce the amount of time it takes to process them.
Last February, Israeli AI technology developer Hour One announced the completion of a $20 million Series A funding round, which the company will use to expand its self-service platform Reals, which allows companies to automatically create human-driven videos from text in minutes.
In October, Descript, an audio transcription editor that takes audio-transcribed text and puts it into a Word document, which can then be edited by an editor or audio producer like a document, announced the completion of a new round of funding led by OpenAI, valuing the company at $550 million.
In December, Runway, a provider of AI photo and video editing software, closed a $50 million Series C round of funding at a post-money valuation of $500 million.
Behind the news:
The generative models used to create photorealistic videos are at the forefront of what can be achieved with deep learning today. As a result, AI video has already achieved the coverage of some short videos by the end of 2022.
While previous work has demonstrated the ability to generate short photorealistic videos, generating long videos that are both coherent and photorealistic, capturing decisive techniques such as remote dependency remains a challenge.
maadaa.ai predicts:
Although there are no phenomenal tools like Stable Diffusion and ChatGPT for the to-C (customer) business, in an internet environment where short and long videos take up a lot of users’ time, AI video tools have a much clearer path to commercialization than their predecessors, for example in marketing and other areas.
Text-to-video gained enormous attention in 2022, as there are no unicorn companies yet, but it has a clear commercial outlook, and is, therefore, worth watching in 2023.
3. Text-to-X
What happened:
In addition to text-to-text, image and video, AI is taking more applications to new levels and becoming part of our everyday lives, such as text-to-coding, bio/chemistry and speech.
In text-to-coding, for example, in 2022, DeepMind launched AlphaCode in February. GitHub opened up access to Copilot in June.
Not to mention the “universal assistant” ChatGPT appeared and many users started to experiment with ChatGPT for writing code in November. However, for more complex programming needs, ChatGPT cannot provide the right answers.
In this case, developers can take the AI-generated code and modify it to save time.
When it comes to text-to-speech, AI can do even more.
For example, Playform AI collaborated with music experts to continue Beethoven’s Tenth Symphony, completing two full movements of over 20 minutes.
AI tools like Soundful can generate royalty-free background music for your videos, streams, podcasts and much more.
podcast.ai, wellsaid and resemble.ai, these AI tools can help people turn text into Synthesized speech.
In biology and chemistry, Cradle is an AI tool that helps biologists design better proteins in record time using powerful prediction algorithms and AI design suggestions.
Harvey is an AI-accelerated research platform that helps life science researchers and medical specialists to discover, interpret and communicate valuable patterns in biological data.
In the game field, AI Dungeon is a free-to-play single-player and multiplayer text adventure game that uses artificial intelligence (A.I.) to generate content.
Moreover, inworld.ai provides a platform for adding advanced NPC behavior and unscripted dialogue to games and real-time media.
Behind the news:
Further improvements in data and computing power will lead to AI with stronger generation effects.
Text-to-X (text-to-any) technology, based on diffusion models and large language models (LLMs), made a breakthrough last year, ultimately because the technology behind it has taken another step forward and can be released to the public for widespread use.
Thanks to some of these technologies, the time it takes to produce AI results is much shorter and the accuracy of the output is much greater.
maadaa.ai predicts:
With all the negative information about people using ChatGPT and Bing, we have collected some queries.
- The results of AI generation are questionable in terms of copyright and accuracy.
- The industry is overheating, and the uneven quality poses data security risks.
- The early generative AI applications are moving towards scale, but retention and differentiation still face difficulties.
- Most of the AI-generated content is not yet ready for direct commercial use and still requires a lot of model fine-tuning and human industry experience to support, augment and process it.
But just because these issues limit the ability of generative AI to become a pervasive technology in the short term, it does not mean that generative AI is not valuable.
In fact, from an article written by Leonis Capital, called ‘Generative AI: State of the Market, Trends and Startup Opportunities’. It says that data is still the king.
“Over the long term, companies with better (perhaps more niche) data for fine-tuning their AI models will show superior outputs for the end customers. That creates a sustainable moat.”
So we have a reason to believe that we will soon see the infinite possibilities of diffusion models, as well as the surprises of multimodal models.
In this case, I am quite excited and look forward to seeing the release of GPT4 and the new experiences it will bring.
[1] https://www.searchenginejournal.com/openai-gpt-4/476759/#close
[2] https://www.pcmag.com/news/artists-sue-ai-art-generators-for-copyright-infringement
[3] https://www.leoniscap.com/blog/generative-ai-technological-trends-and-startup-opportunities
Further reading:
Chinese version ChatGPT — Hype or Hope?
Diffusion Models : Unconditional&Conditional Image Generation
