





If you missed out on our previous articles of this series, please check the link below for more information.
1. Towards Multimodal LLMs — Video-Language Pre-Trained models
2. Towards Multimodal LLMs — Video-Language Pre-Trained Models: Introduction
3. Towards Multimodal LLMs — Recent Progress and applications of Video-Language Pre-trained Models
~~~~~
As described in previous sections, the scale and quality of pre-training datasets play an important role in learning robust visual representations. For another, transformer-based models require more large-scale training data than counterpart convolutional networks. There are some essential datasets emerged to facilitate video-language pre-training, such as Howto100M and Kinetics.
We will introduce these datasets in detail and simply divide these datasets into two categories, i.e., label-based datasets and caption-based datasets.
Label-based Video Datasets
Kinetics dataset
The kinetics [5] dataset is a large-scale action recognition dataset with diverse categories.
Kinetics collects large-scale, high-quality URL links of up to 650,000 video clips that cover 400/600/700 human action classes. The videos include human-object interactions, such as playing instruments, as well as human-human interactions, such as shaking hands and hugging. Each action category has a minimum of 400/600/700 video clips. And according to the action categories and video number, the kinetics can be divided into three datasets: Kinetics400, Kinetics600, and Kinetics700. Each clip has a single action class annotation and lasts around 10 seconds. Examples of Kinetics can be seen in Fig 10. Kinetics covers diverse scenes and actions in the real world. Because of the large number of video numbers, Kinetics is often used to per-train video models.

Link: https://www.deepmind.com/open-source/kinetics
AVA Dataset
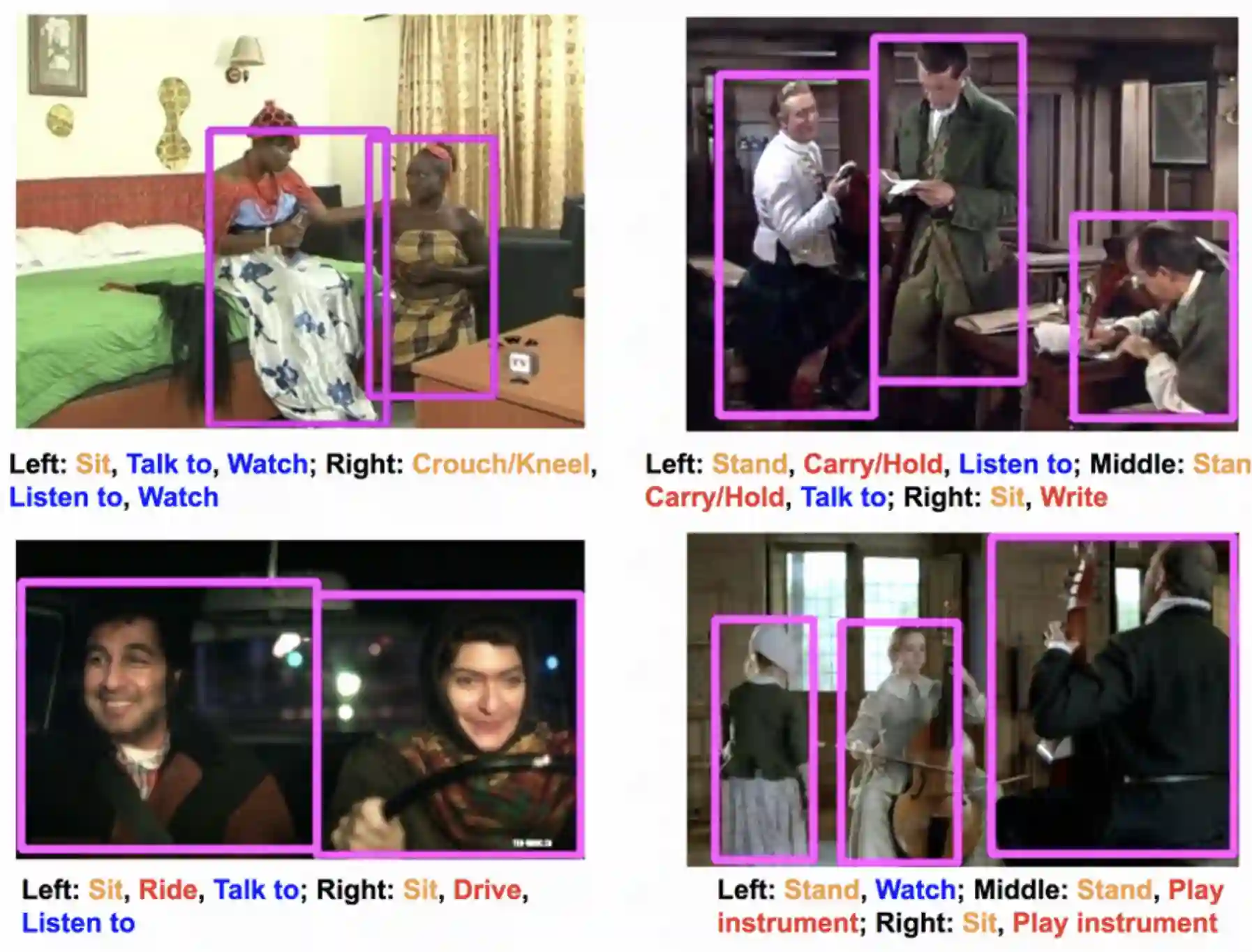
The AVA dataset[6] densely annotates 80 atomic visual actions in 15-minute movie clips, where actions are localized in space and time, resulting in 1.62Million action labels with multiple labels per human occurring frequently. The key characteristics of this dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatial-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. Fig11 illustrates examples of the AVA dataset. The annotation is person-centric at a sampling frequency of 1 Hz. Every person is localized using a bounding box, and the attached labels correspond to (possibly multiple) actions being performed by the actor.

Link: https://research.google.com/ava/
Caption-based Video Datasets
ActivityNet Captions
ActivityNet Captions[7] contains 20k videos amounting to 849 video hours with 100k total descriptions, each with its unique start and end time. Each sentence has an average length of 13.48 words, which is also normally distributed. This data is often used for video-text retrieval or video-moment retrieval tasks. Fig 12 shows an example of ActivityNet caption datasets, this video is divided into five segments, and each segment has a descriptive sentence.

Link: https://paperswithcode.com/dataset/activitynet-captions
YouCook2
YouCook2[8] is one of the vision community’s largest task-oriented instructional video datasets. It features 2000 lengthy, uncut videos from 89 cooking recipes, with an average of 22 videos for each individual recipe. Each video’s procedure stages are labeled with time bounds and stated in instrumental English. The videos were obtained from YouTube, and all feature a third-person perspective. All videos are unrestricted and can be created by anybody in their own homes using unfixed cameras. YouCook2 provides a wide variety of recipe types and cooking methods from across the world.
The total video time is 176 hours, with an average length of 5.26 mins for each video. Each video captured is within 10 mins and is recorded by camera devices.

Link: http://youcook2.eecs.umich.edu/
Howto100m
HowTo100M[9] is a large-scale dataset of narrated videos with an emphasis on instructional videos where content creators teach complex tasks with an explicit intention of explaining the visual content on screen. This dataset contains more than 136 Million video clips with captions sourced from 1.2M Youtube videos. And there are 23k activities from domains such as cooking, handcrafting, personal care, gardening, or fitness. For large-scale datasets, Howto100m becomes the gold-standard dataset for video-language pre-training methods.

Link: https://www.di.ens.fr/willow/research/howto100m/
WebVid
There are two splits of WebVid datasets[10], i.e., WebVid-2M and WebVid-10M. And the most popular version is the WebVid-2m, which comprises over two million videos with weak captions scraped from the internet. Web2vid dataset consists of manually generated captions that are, for the most part well formed sentences. In contrast, HowTo100M is generated from continuous narration with incomplete sentences that lack punctuation. So the WebVid dataset is more suited for video-language pre-training tasks for learning open domain cross-modal representations. As shown in Fig15, the WebVid dataset contains manually annotated captions.

Link: https://m-bain.github.io/webvid-dataset/
HD-VILA
High-resolution[11] and Diversified Video Language pretraining model (HD-VILA)dataset is recently introduced as a large-scale dataset for video-language pre-training. This data is 1) the first high-resolution dataset consisting of 100Million video clips and sentence pairs from 3.3 million videos with 371.5K hours of 720p videos, and 2) the most diversified dataset covering 15 popular YouTube categories.

Link: https://github.com/microsoft/XPretrain/tree/main/hd-vila-100m
