





Abstract
With the development of video applications, many videos are uploaded to the internet. Therefore, how to utilize the video and corresponding weak captions to perform representation learning has recently become a hot topic. This paper will detail a review of the large-scale video-language pre-training task with its recent progress, downstream applications, fundamental datasets, and techniques.
Introduction
Pre-training & Fine-tuning
Pre-training & Fine-tuning is a standard learning paradigm in the current deep learning algorithm: first, pre-training the model on a large-scale dataset in a supervised or unsupervised manner, followed by fine-tuning the pre-trained model for specific downstream tasks on smaller datasets. Such a paradigm eliminates the need to train fresh models from scratch for distinct tasks or data sources. It has been demonstrated that pre-training on bigger datasets facilitates the acquisition of universal representations, enhancing performance and reducing the computation costs of subsequent tasks.

Most previous methods utilize self-supervised learning to pre-train the backbone model on the ImageNet[1] dataset that contains 14,197,122 annotated images according to the WordNet hierarchy. With the development of unsupervised learning, large-scale dataset without labels have been leveraged to perform the pre-training and achieves remarkable performance in both NLP and CV area.
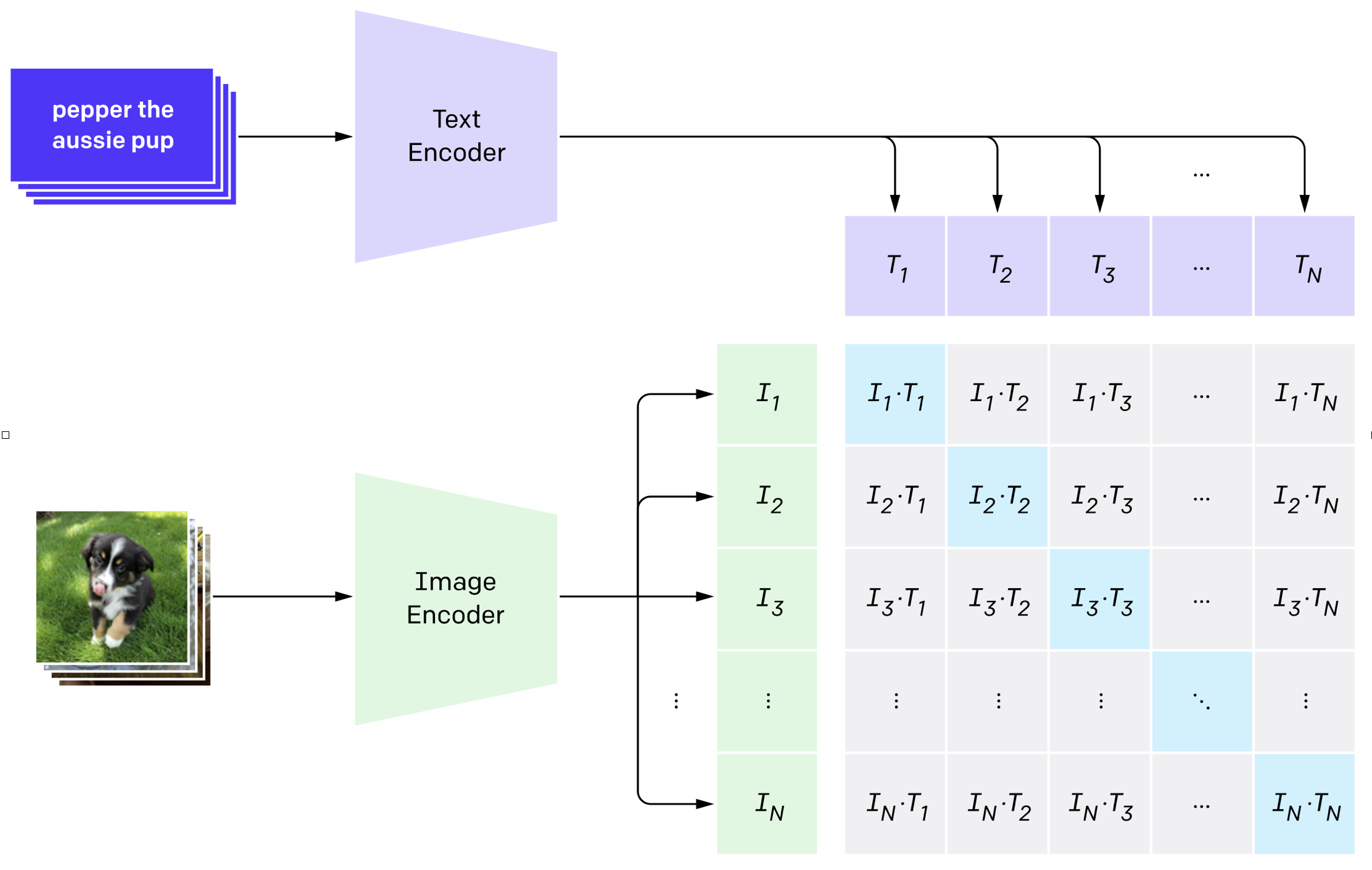
As shown in Figure 1, the pic shows the pipeline model learning pipeline in NLP. First, the model, such as Bert[2], will per-training on large-scale unlabeled datasets, e.g., Wikipedia, and BookCorpus, with self-supervised learning. Then the pre-trained model weights that contain general representation will be fine-tuned on the smaller dataset, such as SQuAD, with Task-specific learning objectives. And finally, the learned model can be used to infer.
Video–Language Pre-training
Video-language pre-training mainly focus on utilizing large-scale video-text data to perform self-supervised/unsupervised learning to obtain generalization representations for downs stream task. The main backbone of this task is the transformer. And the proxy task that facility self-supervised or unsupervised learning is important to obtain robust representations.
We will briefly introduce the main proxy tasks for video-language pre-training.
Masked Language Modeling(MLM) is first adopted as a proxy task during the pre-training of BERT [1]. In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard Language Modeling(LM). In all of our experiments, BERT masks 15% of all WordPiece tokens in each sequence at random. Figure 5 is an illustration of MLM in the BERT. In this case, “boring” is masked, and the model is asked to predict the proper task given the context of the text. In Video-Language pre-training, MLM not only learns the underlying co-occurrence associations of a phrase but also mixes visual information with the text.

Masked Frame Modeling (MFM) is similar to MLM in that the video sequence is substituted for the phrase. In other words, frame tokens are masked for prediction based on contextual frames and the input text’s semantic restrictions.
Language Reconstruction (LR) LR is a generative task that aims to enable the pre-trained model with the ability of video caption generation. The difference between LR and the masked language method (MLM and MMM with all text tokens being masked) is that LR generates sentences from left to right, which means the model only attends to the former text tokens and video tokens when predicting the next text token.
Video Language Matching (VLM) aims to learn the alignment between video and language. There are different task forms of VLM, and we classify them into 1) Global Video Language Matching (GVLM) and 2) Local Video Language Matching (LVLM). For the GVLM, one objective function is adapted from the Next Sentence Prediction (NSP) task used by BERT[3], which takes in the hidden state of a special token [cls] to an FC layer for binary classification.
Sentence Ordering Modeling (SOM) SOM is first proposed in VICTOR, which aims to learn the relationships of text tokens from a sequential perspective. Specifically, 15% of sentences are selected, randomly split into three segments, and shuffled in a randomly permuted order. There- fore, it can be modeled as a 3class classification problem. To be specific, after multi-modal fusion, the embedding of a special token [cls] is input into the FC layer, followed by a softmax operation for classification.
Frame Ordering Modeling (FOM) FOM is proposed in VICTOR and HERO. The core idea is to randomly shuffle a fixed percentage of frames and predict their original order. VICTOR randomly selects to shuffle 15% of frames. The embedding of each shuffled frame is transformed through an FC layer, followed by softmax operation for N-class classification, where N is the maximum length of the frame sequence. HERO also randomly selects 15% of frames to be shuffled. The embeddings of all frames are transformed through an FC layer, followed by a softmax operation to produce a probability.
(To Be Continued)
Further Reading:
Towards Multimodal LLMs — Recent Progress and applications of Video-Language Pre-trained Models
Towards Multimodal LLMs — Video-Language Pre-Training Methods
