





With the development of video applications, many videos are uploaded online. Therefore, how to utilize the video and corresponding weak captions to perform representation learning has recently become a hot topic. This paper will review the large-scale video-language pre-training task with its recent progress, downstream applications, fundamental datasets, and techniques.
1. Introduction
The first part of this series reviewed the progress, applications, datasets, and techniques of large-scale video language pre-training. This task uses weak captions and videos to perform representation learning. A standard learning paradigm in deep learning, pre-training & fine-tuning, is used to pre-train models on large datasets and then fine-tune them for specific tasks on smaller datasets. This eliminates the need to train new models for different tasks and reduces computational costs.
Pre-training is often done using self-supervised learning on large datasets such as ImageNet, and unsupervised learning has also shown remarkable performance in both NLP and CV domains. The pre-trained model weights are then fine-tuned on smaller datasets for task-specific learning goals.
Video language pre-training uses large-scale video text data for self-supervised/unsupervised learning to obtain generalization representations. The main proxy tasks include Masked Language Modeling (MLM), Masked Frame Modeling (MFM), Language Reconstruction (LR), Video Language Matching (VLM), Sentence Ordering Modeling (SOM), and Frame Ordering Modeling (FOM). These tasks focus on language prediction, frame prediction, sentence generation, video-language alignment, sentence ordering, and frame ordering, respectively. The tasks aim to learn co-occurrence associations, semantic restrictions, video caption generation, alignment, and relationships from a sequential perspective.
View More: Towards Multimodal LLMs — Video-Language Pre-Trained models

2. Recent Progress and Applications
Recent advances in pre-training models have highlighted the importance of dataset size for representation learning. As a result, researchers are using large-scale, weakly labeled cross-modality data from the Internet, such as image-caption pairs and video-caption data. This has led to a surge in the study of cross-modal tasks, particularly vision-language and video-language tasks.
An important development in vision-language pre-training is Contrastive Language-Image Pre-Training (CLIP), which uses contrastive loss to learn multimodal representations from weakly supervised data. The model, trained on a dataset of 400 million image-text pairs, has shown impressive results in zero-shot visual recognition tasks such as image classification.
Video data, which is inherently multimodal with elements such as titles, audio, and narration, has also seen progress. Large video datasets such as Howto100M, which contains 136 million videos with narrative text data, have been proposed. This has spurred the development of video language pre-training, opening up new areas for video understanding tasks.
The Transformer model, originally proposed for machine translation, has shown excellent performance in computer vision. It computes the similarity of elements and aggregates long-range dependencies with these elements, allowing training on larger datasets.
Video language pre-training aims to transfer knowledge from large datasets to downstream tasks, which should include both text and video input. Downstream tasks include video-text retrieval, action recognition, video question answering, and video captioning. Each task requires a different approach to transferring information from pre-training to downstream tasks, highlighting the importance of compatibility between pre-training and downstream tasks.
View More: Towards Multimodal LLMs — Recent Progress and Applications of Video-Language Pre-trained Models

3. Open Datasets for Video-Language Pre-Training
The scale and quality of pre-training datasets play a crucial role in learning robust visual representations, especially for transformer-based models. Key datasets for video-language pre-training can be categorized into two types: label-based and caption-based datasets.
Label-based Video Datasets:
1. Kinetics: A large-scale action recognition dataset with diverse categories, containing up to 650,000 video clips that cover 400/600/700 human action classes.
2. AVA: Densely annotates 80 atomic visual actions in 15-minute movie clips, resulting in 1.62M action labels with multiple labels per human occurring frequently.
Caption-based Video Datasets:
1. ActivityNet Captions: Contains 20k videos amounting to 849 video hours with 100k total descriptions, each with its unique start and end time.
2. YouCook2: One of the largest task-oriented instructional video datasets, featuring 2000 lengthy, uncut videos from 89 cooking recipes.
3. Howto100m: A large-scale dataset of narrated videos, containing more than 136M video clips with captions sourced from 1.2M YouTube videos.
4. WebVid: A dataset of over two million videos with weak captions scraped from the internet. There are two versions: WebVid-2M and WebVid-10M.
5. HD-VILA: The first high-resolution dataset consisting of 100M video clips and sentence pairs from 3.3M videos with 371.5K hours of 720p videos.
These datasets have been instrumental in the advancement of video-language pre-training methods, providing diverse and large-scale data for training robust models.
View more: Towards Multimodal LLMs — Open Datasets for Video-Language Pre-Training

4. Video-Language Pre-Training Methods
Recent video-language pre-training methods mainly use transformers as feature extractors for learning from large-scale multi-modal data. These methods can be categorized into two types: Single-Stream and Two-Stream.
Single-Stream Methods:
1. VideoBERT: The first to explore Video-Language representation with a transformer-based pre-training method.
2. HERO: A single-stream video-language pre-training framework that encodes multimodal inputs in a hierarchical structure.
3. ClipBert: Proposes a generic framework that enables affordable end-to-end learning for video-and-language tasks by employing sparse sampling.
4. DeCEMBERT: Developed to address the issue that automatically produced captions in pre-training datasets are noisy and occasionally misaligned with video material.
5. VATT: A method for learning multimodal representations from unlabeled data using convolution-free Transformer structures.
6. VIOLET: Proposes a transformer framework that end-to-end models the temporal dynamics of video.
7. ALPRO: A single-stream framework for video-language pre-training that proposes a Video-Text Contrastive to facilitate multi-modal interaction.
Two-Stream Methods:
1. CBT: Proposes contrastive noise estimation (NCE) as the loss target for Video-Language learning.
2. UniVL: Proposed to model for both multi-modal understanding and generation.
3. Frozen in Time (FiT): Aims to learn joint multi-modal embedding to enable effective text-to-video retrieval.
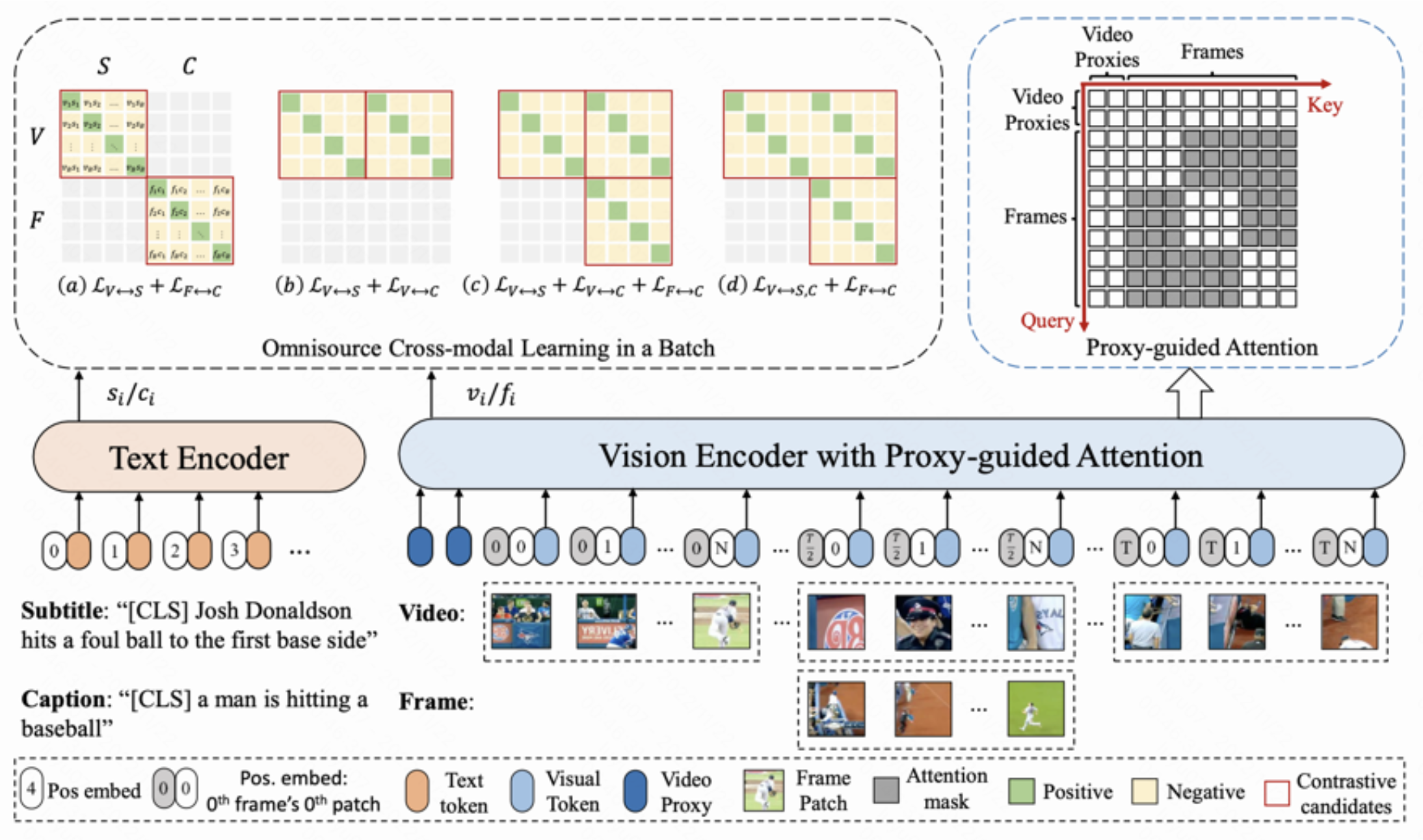
4. CLIP-ViP: Proposes to pre-train the CLIP model on video-language data to further extend the visual-language alignment to the video level.
These methods have shown promising results in various applications, including action recognition, video captioning, action anticipation, and video segmentation. The choice between single-stream and two-stream methods depends on the specific requirements of the task, with single-stream methods generally capturing more fine-grained relationships between text and video, and two-stream methods offering more flexibility by extracting different modalities’ features separately.
View more: Towards Multimodal LLMs — Video-Language Pre-Training Methods

