





 Standard Datasets
Standard DatasetsChinese & English & Tibetan & Uyghur Language Dataset
Sample






Specification
Dataset ID
MD-OCR-007
Dataset Name
Chinese & English & Tibetan & Uyghur Language Dataset
Data Type
 Image
ImageVolume
About 38k
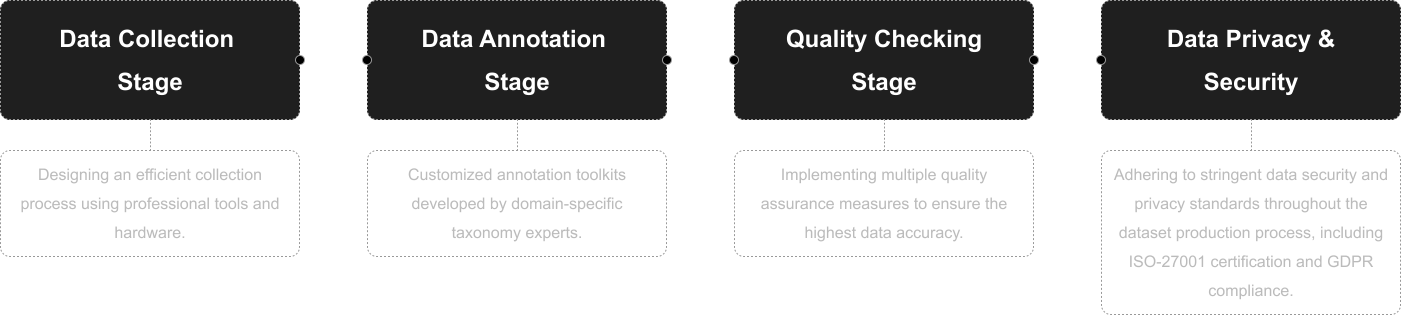
Data Collection
Data collection equipment include phones, cameras and tablets. Images include product packages, store names, signposts, posters, parking lots, car stickers, food packaging, signs and book covers, etc.
Annotation
Bounding Box+Text
Annotation Notes
All text include simplified Chinese, English, numbers, and punctuation marks (comma, period, colon, etc.).
Application Scenarios
Tourism;Retail
Quality Assurance
Related products
Any further information, please contact us.
