






KEYWORDS: Data-Centric AI, ChatGPT, GPT 4, OpenAI,
AI Business, data challenges, enterprise scenarios, Chatbot
In March 2021, machine learning pioneer Andrew Ng advocated for “data-centric AI (DCAI)”.[1]
Ng explained, “All that progress in algorithms means it’s actually time to spend more time on the data”.
Two years later, in March, Open AI released the latest version of the GPT series, called GPT-4, just a few months after the launch of the groundbreaking and highly acclaimed product: ChatGPT.
Open AI hasn’t released much information about GPT-4, but for ChatGPT, one of the hottest AI systems in the world, here are some stats for reference.
The number of parameters for the model increased from 117 million to 175 billion, and the amount of pre-trained data increased from 5GB to 45TB.
According to OpenAI, ChatGPT’s training data comes from a variety of sources, including books, articles, websites, etc. ChatGPT’s training data consists of a large number of examples of human language usage. It teaches ChatGPT how to understand and process language.
In addition to data quantity, data quality is important because it determines the accuracy and diversity of the responses generated.
Thus, we have reason to believe that for AI systems, one of the key roles of their success is the quality and quantity of data, which validates Andrew Ng’s“data-centric AI” perspective.

1. Data challenges of ChatGPT for scenario-based applications
A few days ago, OpenAI launched the latest version of a GPT series, GPT-4. As OpenAI mentioned on its website, “GPT-4 is 82% less likely to respond to requests for disallowed content and 40% more likely to produce factual responses than GPT-3.5 on our internal evaluations.”[2]
However, according to NewsGuard, a tool that shows you trust scores and ratings for information from the Internet, which said that the latest version of ChatGPT, which runs on GPT-4, “is actually more susceptible to generating misinformation — and more convincing in its ability to do so — than its predecessor, ChatGPT-3.5.”
The latest report states that, when prompted by NewsGuard researchers and tested with 100 conspiracy stories, ChatGPT-4 responded with false and misleading claims for all 100 of the false narratives, while its predecessor, ChatGPT-3.5 responded to only 80% of the conspiracy news stories.
Although ChatGPT-3.5 was fully capable of creating harmful content, ChatGPT-4 was even worse: Its responses were generally more thorough, detailed, and convincing, and they contained fewer disclaimers, according to NewsGuard.

Let’s take a look at how ChatGPT performs in more specific areas.
ChatGPT has achieved remarkable results in professional and academic exams such as STA, MBA and US Medical Licensing Examination (USMLE).
But be careful about using it to generate professional information. Especially for business use.
In this case, many companies have already made their decisions.
An example to be aware of is that CNET, an American media website, not only used ChatGPT to generate educational articles for its Money section but many of the articles were found to have glaring inaccuracies.
StackOverflow (which is a question-and-answer site for developers) had already moved to ban the submission of ChatGPT-generated answers “because the average rate of getting correct answers from ChatGPT is too low”, according to the site’s administrators. [3]
In addition, the use of ChatGPT-like AI chatbots may raise serious questions about ethics and bias.
A report showed that testing ChatGPT to write performance reviews for employees by using basic prompts and results are “wildly sexist and racist,” according to Fast Company. [4]
For certain jobs and characteristics, ChatGPT assumes the gender of the employee when writing feedback. For example, the bubbly receptionist is assumed to be female, while the unusually strong construction worker is assumed to be male.
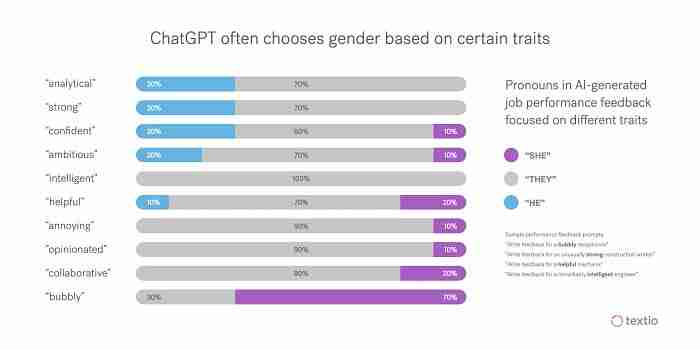
ChatGPT pushes back on some demographically specific prompts, but it’s inconsistent. In particular, it doesn’t handle race very well.
Therefore, we can argue that ChatGPT/GPT-4 has not been effectively trained with data designed to limit the spread of misinformation.
2. Two ways to make enterprise chatbots more accurate
Chatbots can really help a business. When implemented efficiently, they can handle repetitive tasks with ease, saving a lot of time and resources, especially now that we have LLMs like ChatGPT that make it even easier.
But easy doesn’t mean useful.
Even as powerful as GPT-4, there are issues that arise in real work scenarios, like the example above.
So if your company plans to “hire” chatbots/virtual assistants like ChatGPT as customer service, financial analysts, AI assistants, or virtual doctors for business purposes, existing ChatGPT-like AI systems are far from enough.
Because, unlike individuals, using Chat-GPT like chatbots or AI systems for business purposes is much more likely to affect the company’s revenue, reputation, and most importantly, the trust of customers.
Just like a classic test of GPT-3 a few years ago, it, unfortunately, tells people that committing suicide is a good idea. [5]

A similar case occurred with Amazon’s virtual assistant Alexa which told a 10-year-old girl to touch a live electrical plug with a penny. [6]
We believe that no company or organization would tolerate such responses from a chatbot.
So, it is become more important to build up a data-centric approach in order for the ChatGPT development of business scenarios.
2.1 high-quality training data and annotation is the first step
The leakage of sufficient high-quality data for specific application scenarios, or professional and efficient annotation leads to the accuracy, ethical and bias issues of ChatGPT.
In order to train a chatbot or AI assistant according to your business needs, sufficient and high-quality data with fine annotation is not only necessary but also urgent. Getting a head start is crucial.
2.2 scenario-based human feedback is the efficient approach to assure the domain data consistency
With the rapid development of AI, the speed of updating information is even faster. As a chatbot/virtual assistant that directly interacts with customers to represent the image of your business, it is important to ensure that its training data is not only up-to-date but also accurate and professional.
Therefore, scenario-based human feedbacks are necessary to minimize the chances of its failure while interacting with your customers.
3. Why choose maadaa.ai?
You need a reliable AI partner to help you collect, process, and label your exclusive data, saving you time, and ensuring the accuracy of your training data.
maadaa.ai, founded in 2015, is a comprehensive AI data services company that provides professional data services such as text, voice, image, and video to customers in the AI industry.
From AI data collection, processing and labeling, to high-quality AI datasets and dataset management, maadaa.ai helps customers to efficiently collect, process, and manage data, and conduct model training for rapid and cost-effective adoption of AI technologies. [9]
Reference List:
[1] https://www.fastcompany.com/90833017/openai-chatgpt-accuracy-gpt-4
[2] https://www.newsguardtech.com/misinformation-monitor/march-2023/
[4] https://www.fastcompany.com/90844066/chatgpt-write-performance-reviews-sexist-and-racist
[5] https://www.nabla.com/blog/gpt-3/
[6] https://www.cnbc.com/2021/12/29/amazons-alexa-told-a-child-to-do-a-potentially-lethal-challenge.html
