






#HumanSegmentationDataset #HumanSegmentation #Datasets #FaceParsing #HumanPartSegmentation
With video conferencing, live broadcasting, real-time communication, Interactive entertainment, and online education, collaboration online has become the main way for people to communicate with the world.
But, all these requests faced a serious issue: there is always something you do not wish others to see. So how to protect your personal privacy while using webcams?
That is why human video segmentation technology went viral and developed rapidly.
Portrait segmentation helps users identify people and backgrounds in real time.
It accurately enhances the visual application experience. Therefore the background will be changed or hidden, which helps to protect our privacy.
Two types of Human video segmentation
There are two types of human video segmentation.
1. Background Blur
For some shooting scenes, we often want to highlight the main characters and portraits and blur the background, which can get better visual effects.
First, background blur needs to achieve the separation of portrait and scene.
Then, add a portrait back after blurring the background.
This technology is wildly used in live broadcasting and real-time communication scenarios.
2. Background replacement
For video conferencing scenarios, background replacement techniques are also important because the background of the participants may not be suitable for sharing and filming.
First, the portrait needs to be separated from the original background, and then the separated portrait is added to the new fixed background.
Background replacement technology also has many applications in some film shooting fields.
For example, for some science fiction scenes that cannot be shot on the spot, the film crews need to re-insert the modeled background image and the segmented portrait.
Nowadays, many electronic devices have similar technologies which can put people anywhere they want by easily changing backgrounds.
The most common example is the filming and video applications on smartphones which bring more excitement and joy to our day-to-day life.
Related Technologies for Machine Learning
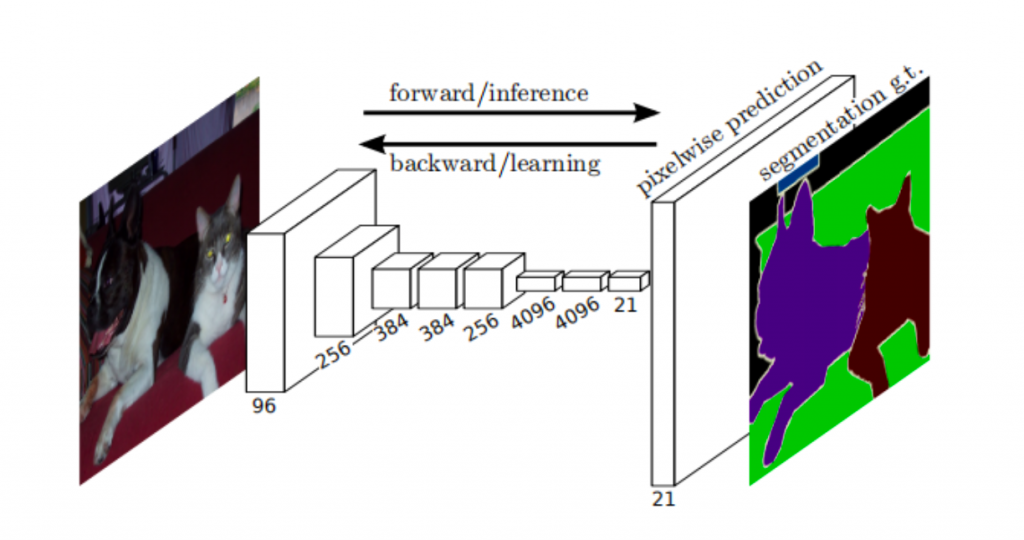
Representative network structure is FCN, which is Fully Convolutional Network. Its model structure is very simple.
For example, VGG is used to extract image features, remove the last full connection layer, use Transpose Convolution of up-sampling to restore feature images of multiple down-sampling to the same size as the original image, and then generate a classified label for each pixel.
Generally, The CNN network will connect the full connection layer after the convolutional layer and map the feature map generated by the convolutional layer into a feature vector of fixed length.
However, FCN needs to classify pixels and accept input images of any size.
FCN uses deconvolution to upsample the feature map of the last convolutional layer to restore it to the same size of the input image, thus generating a prediction for each pixel while retaining the spatial information in the original input image.
Finally, pixel-by-pixel classification is performed on the feature map of upsampling.
Related Commercial datasets by maadaa.ai
Here are some highly searched and mentioned datasets from maadaa.ai to help you carry on model training, in order for fast and low-cost AI technology introduction.
1. Single-person Portrait Matting Dataset (MD-Image-003)
MD-Image-003 is a single-figure portrait segmentation dataset with a total of about 5W images. The dataset, collected from the Internet, includes a variety of poses, hairstyles and landscapes. The image resolution is greater than 1080 x 1080.

Link: https://maadaa.ai/dataset/single-person-portrait-matting-dataset/
2.. Human Portrait Matting Dataset (MD-Video-004)
MD-Video-004, the data type is Video. About 4.1k Images are from the internet. Resolution ranges from 1280 x 720 to 2048 x 1080. Annotation types are Instance Segmentation, Semantic egmentation

Link: https://maadaa.ai/dataset/human-portrait-matting/
3. Facial Parts Semantic Segmentation Dataset (MD-Image-019)
MD-Image-019, face area categories include skin, left eye, right eye, left eyebrow, right eyebrow, nose, left ear, right ear, mouth, upper lip, lower lip, hair, cap, glasses, wearing accessories, neck, clothing, etc.
About 2,791.7k Images were collected online and offline, with resolutions ranging from 300 x 300 to 4480 x 6720.

Link: https://maadaa.ai/dataset/facial-parts-semantic-segmentation/
4. Eastern Asia Single-person Portrait Segmentation Dataset (MD-Image-004)
MD-Image-004 is a segmentation dataset of East Asian portraits, with a total of about 5W images. The background includes indoor, outdoor, street scenes and sports.

Link: https://maadaa.ai/dataset/eastern-asia-single-person-portrait-segmentation-dataset/
5. Human Body High Precision Segmentation Dataset (MD-Image-022)
MD-Image-022, the data type is Image. About 424.8k Shoot manually and collected from the internet, image resolution ranges from 316*600 to 6601 x 9900.
High precision segmentation of human bodies, including limbs (left and right arms or upper and lower arms + left and right legs or legs), clothing (coats, jackets, dresses, dresses, dresses, skirts, coats, socks, trousers, ties), facial thinning (eyebrows, eyes, nose, mouth, beard), skin (skin color differentiates in some cases), caps, hair, accessories (Accessories, bags, belts, gloves, scarves), backgrounds, etc.)

Link: https://maadaa.ai/dataset/human-body-high-precision-segmentation/
6. Human Body Parts Fine Segmentation Dataset (MD-Video-005)
MD-Video-005, diversified scenes such as dancing, talent shows, movies, TV stories. Includes 19 categories: background, face, hair, top, left arm, right arm, trousers, left leg, right leg, skirt, left shoe, right shoe, bag, etc.

Links: https://maadaa.ai/dataset/high-precision-human-body-segmentation/
7. Human Body Semantic Segmentation Dataset (MD-Image-005)
MD-Image-005, this data type is Images. About 100k Internet-collected human body images with evenly distributed gender and age, covering multiple countries, variable postures, hairstyles and scenarios.
Fine labeling of 19 human body areas, including face, left/right arm, left/right leg, hat, hair, coat and so on.

Link: https://maadaa.ai/dataset/human-body-semantic-segmentation-dataset/
Further Reading:
Face Parsing: use cases and open datasets
Video face segmentation: use cases and open datasets
AI for virtual fitting: inspired by datasets (Open & Commercial)
AI for fake Detection in Fashion and E-commerce industries: The related open & commercial datasets
