





maadaa.ai collected benchmark datasets for the VMR task in this section. Typically, a VMR dataset consists of a collection of videos. Each video may include one or more annotations, sometimes known as moment-query pairs. Each annotation corresponds to a certain moment in the video with a query.
Multiple datasets for VMR are derived from separate settings and exhibit distinct properties.
1. Open Datasets
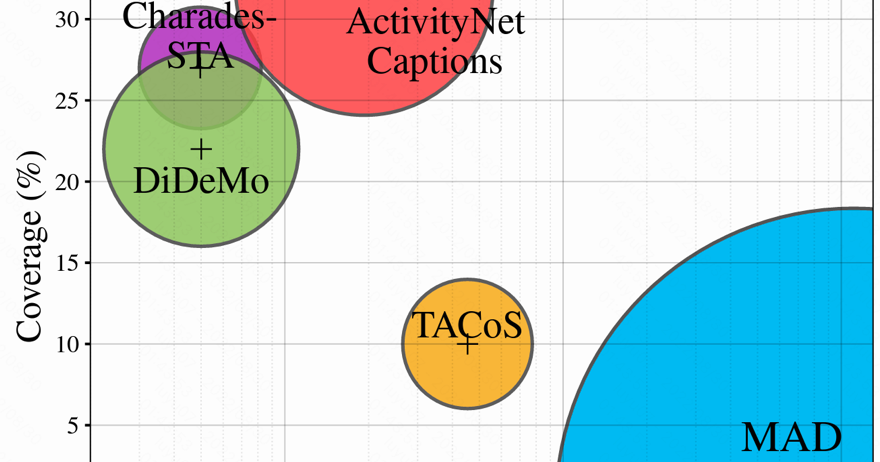
As shown in Fig 22, the video lengths of different datasets are presented and the circle size measures the language vocabulary diversity. Coverage is defined as the average % duration of moments with respect to the total video duration. Earlier datasets such as Charades or DiDeMo have smaller video lengths and vocabulary sizes. MAD is the newest presented dataset that is orders of magnitude longer in duration than previous datasets, annotated with natural, highly descriptive, language grounding with very low coverage in the video.
1.1 DiDeMo Dataset
The DiDeMo[18] dataset is one of the first datasets for the VMR dataset. It is rooted in the YFCC100M [30] dataset, which contains over 100k Flickr videos depicting diverse human activities. Over 14,000 videos are selected at random by Hendricks et al., who then divide and identify video segments. Since each segment consists of five-second video snippets, the duration of each ground-truth moment is also five seconds. They say that this strategy eliminates labeling ambiguity and expedites the validation process. However, such a length-fixed issue simplifies retrieval because it reduces the search space to a smaller group of candidates. The DiDeMo dataset contains 10,464 videos and 40,543 annotations, with an average of 3.87 annotations per video. Note that the videos are released as extracted visual features. For another, Hendricks et al. collect a TEMPO dataset, which is built upon DiDeMo, by augmenting language queries with a template model (template language) and human annotators (human language). Compared to DiDeMo, TEMPO contains more complicated human-language questions. Fig 22 shows an example of the DiDeMo dataset.

Link: https://paperswithcode.com/sota/video-retrieval-on-didemo
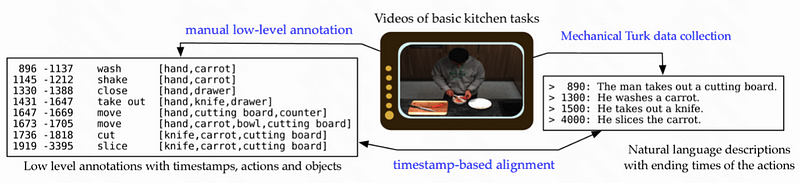
1.2 TACoS dataset
TACoS dataset [62] is derived from the MPII Cooking Composite Activities dataset [63], which was originally designed for human activity recognition in a specific context, i.e., composite cooking activities in a kitchen. It includes 127 complicated videos of cooking activities, with each video containing many segments annotated with language descriptions illustrative of people’s cooking behaviors. Fig 23 shows an example of TACOS. Each video in TACOS has two types of annotations: (1) fine-grained activity labels with temporal location and (2) natural language descriptions with the temporal location. The natural language descriptions are created by crowdsourcing annotators who describe the video material using phrases. There are 18,818 moment-query pairs in TACOS. The average duration of a video is 286.59 seconds, the average length of a moment is 6.10 seconds, and the average length of a search query is 10.05 words. On average, TACoS videos have 148.17 annotations. Zhang et al. [22] make available a modified version of TACOS(2DTAN). The TACOS(2DTAN) database has 18,227 annotations. There are 143.52 annotations per video on average. The average moment duration and question lengths are 27.88 seconds and 9.42 words, respectively.
1.3 Charades-STA dataset
Charades-STA is built by Gao et al [2] from the Charades dataset, which was originally gathered for video activity detection, and is comprised of 9848 videos portraying human indoor daily activities. Charades has 157 action categories and 27,847 sentence descriptions at the video level. Based on Charades, Gao et al. [2] build Charades-STA using a semi-automatic workflow that first extracts the activity label from the video description and then aligns the description with the original label-indicated time intervals. The resulting (description, interval) pairs can therefore be viewed as the (sentence query, target segment) pairs for the VMR task. Since the length of the original description in Charades-STA is rather short, Gao et al. [2] increased the description’s complexity by mixing consecutive descriptions into a more complex sentence for the test. Consequently, Charades- STA includes 13,898 sentence-segment pairs for training, 4,233 simple sentence-segment pairs (6.3 words per sentence), and 1,378 complex phrase-segment pairs for testing (12.4 words per sentence).

Link: https://prior.allenai.org/projects/charades
1.4 ActivityNet Dataset
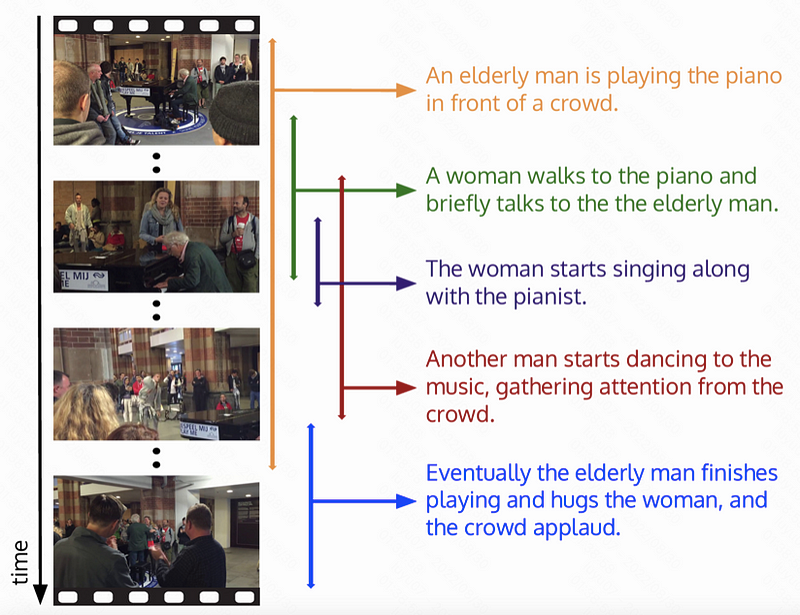
Krishna et al. [60] have created ActivityNet Captions for dense video captioning tasks. However, the sentence-moment pairs in this data set can be adopted naturally for the VMR tasks. The videos are extracted from the ActivityNet dataset, a benchmark for human activity comprehension. ActivityNet contains videos from 203 activity classes, averaging 137 untrimmed videos per activity class and 1.41 activity instances per video. The official test set of ActivityNet Captions is withheld from the competition, and existing VMR methods rely primarily on the official “val1” and/or “val2” development sets as test sets. ActivityNet Captions contain the largest amount of videos, and it aligns videos with a series of temporally annotated sentence descriptions. ActivityNet Captions comprises a total of 14 926 videos and 71 953 annotations, with an average of 4.82 temporally localized sentences per video. The average duration of a video and a moment is 117.60 and 37.14 seconds, respectively. The average query is approximately 14.41 words long.
Link: http://activity-net.org/download.html
1.5 MAD Dataset
MAD [31] is a large-scale dataset containing popular movies. MAD aims to avoid the hidden biases (described in previous) of earlier datasets and offer accurate and unbiased annotations for the VMR task. Soldan et al. [31] utilize a scalable data collection technique rather than depending on crowd-sourced annotations to produce the annotations. They transcribe the audio description track of a movie and exclude sentences linked with the actor’s speaking in order to obtain highly descriptive sentences based on long-form movies. MAD comprises 650 films with a combined runtime of almost 1,200 hours. The average video length is approximately 110 minutes. Each video in MAD is an uncut feature film. MAD has 348,600 inquiries with a 61,400-word vocabulary. The average question is 12.7 words long. The short average duration of temporal moments in MAD makes the localization process more difficult.

Fig 27 shows an example of MAD dataset, the figure selects the movie “A quiet place” as a representative example. There are numerous densely distributed temporally grounded sentences in the film. The collected annotations can be extremely extensive, containing references to people, acts, locations, and other supplementary information. Due to the nature of the film’s plot, the characters remain silent for the overwhelming portion of the film, necessitating audio descriptions for visually impaired spectators.
Link: https://github.com/Soldelli/MAD
2. The strength of maadaa.ai
maadaa.ai, founded in 2015, is a comprehensive Al data service company supplying the Al industry with professional data services in text, voice, image, and video data types. From Al data collection to data processing and data labeling, and Al dataset management, maadaa.ai helps customers efficiently capture, process, and manage data, and carry on model training for fast and low-cost Al technology introduction.
maadaa.ai’s global data collection and labeling network spans more than 40 countries, allowing maadaa.ai to provide standardized Al data collection, processing, labeling, acceptance, and delivery services to industrial customers.
Further Reading:
To Capture the Highlighting Moments in Video — Video Moment Retrieval and Enabling Datasets
