






#Fashion #personalization #AI #Ecommerce #FakeDetection #VirtualFitting
The combination of AI technology and fashion has become a very active research topic in recent years, which provides a new power for the development of the fashion industry.
The biggest challenge facing the application of AI technology in fashion is that it will face complex real-life scenes, such as clothing with a certain degree of occlusion and complex shapes. It is still a big challenge to understand fashion images.
Supporting multi-scene Fashion data integration is the key to AI technology research and innovation. Based on years of accumulation of maadaa.ai in Fashion datasets and the latest progress of academia and industry, we classify Fashion AI applications and technologies:
In terms of fashion applications, it is mainly divided into the virtual fitting, fashion image caption, text retrieval for clothing content, fake detection of clothing, and Content-Based Recommendations.
According to typical AI technology, it is mainly divided into image classification, image segmentation, cross-modal retrieval, image generation, 3D reconstruction, target detection and key point detection.
Application scenarios and technologies1.1 Application Scenarios
Clothing datasets can serve a variety of application scenarios, and deep learning can design relevant model structures according to the requirements of different scenarios, promoting the development of this field. The application scenarios of Fashion datasets are summarized as follows.
1.1.1 Clothing Retrieval By Image
People usually see some beautiful clothes and hope to find the source of purchase. Image search for clothing is to input photos into the shopping apps and return the same clothing for consumers to purchase.
Clothing Retrieval by image, more popularly known as Visual Search, has become one of the most commonly used for shoppers.
Customers just need to upload a screenshot from Instagram or Pinterest post, or a photo you shot. Then you will find out similar or even the exact same products.
For some shoppers, this is a higher-priority search option than typing keywords.
Nowadays, more online shopping applications and platforms use visual search, such as Shein, Venca, Pinterest, etc.
Here is a video example from Venca online platform, it takes less than 30 seconds to how you can use visual search to order your favorite new outfit.
Venca Visual Search|Youtube Video
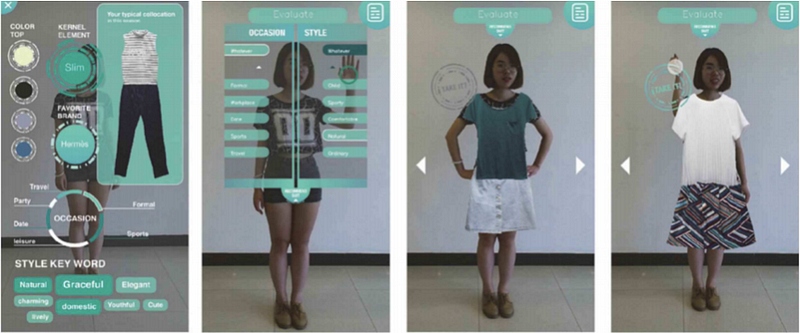
1.1.2 Virtual Fitting
Consumers want to see 3D displays while shopping online, and virtual fitting is coming into being. The Virtual fitting allows consumers to intuitively feel the dressing effect through 3D or 2D mapping of characters and clothing images to the screen.

Regular fashion retailers use this technology by putting up large mirrors in-store. The mirror is commonly called Smart Mirror which in fact is a display screen.
It uses VR or AR to allow customers to virtually try on different styles and sizes of clothing, get personalized outfit suggestions, or play with different shades of makeup.
Brands like COS and Charlotte Tilbury use physical smart mirrors in their stores.
Some bands and retailers use smartphone Apps, such as Gucci, Amazon and 1822 Denim.
There are some virtual fitting Apps for brands and retailers. For instance, style.me, YouCam Makeup, etc.
Please click the link below to read more.
AI for virtual fitting: application scenarios and enabling technologies
1.1.3 Fashion Image Caption
As there are a large number of clothing pictures on the Internet, it would be a huge project to label out the characteristics of clothing pictures one by one manually. If we can automatically generate some descriptions of pictures through deep learning, it will greatly improve efficiency.

1.1.4 Clothing Retrieval By Text
When using the browser and online app shopping software, we sometimes do not know which specific clothing we want to choose, and we usually input text for retrieval according to our own needs.
However, there are a lot of fake titles on the Internet (business titles are inconsistent with the picture content), so the technology of text searching the picture content of clothing is needed to realize the pairing of text and clothing.
How does it work? The technology can enhance product tags with AI-powered deep tagging. For instance, image-based tags from vertical-specific attributes and their synonyms.

1.1.5 Fake Detection of Clothing
Counterfeits are quite painful for both luxury and famous fashion brands but they can be even more of a headache for digital re-sellers.
A lot of phenomena of selling pirated clothes in shopping apps.
Fortunately, machine learning and deep learning methods can find their use in anti-counterfeiting applications.
The counterfeit details of pirated pictures can be identified through clothing counterfeit detection technology, to eliminate the phenomenon of infringing on consumers.
Brands like Amazon, Alibaba, Goat and Entrupy are the benchmarks for what is done in using fake detection technology.
maadaa.ai also wrote an article about AI for fake Detection. To read the full version, please click:
AI for fake Detection in Fashion and E-commerce industries: Use Cases and technologies
Furthermore, here is a video about how Entrupy’s Luxury Authentication Work.
【Video】How to use Entrupy Luxury Authentication|Vimeo
1.1.6. Content-based Recommendation
Shopping apps often need to recommend users’ preferences, classify them automatically according to the pictures they browse, and then recommend similar clothes to users to promote consumption.
Nowadays, online shopping platforms take this technology to the next level. online shopping platforms nowadays are becoming more like personal assistants to each customer.
Topics like clothing retrieval by image and text, fashion image caption and content-based recommendation can also be grouped into: AI-powered personalization in E-commerce and Fashion industries.
1.2 Application Technology
Deep learning models can enable innovative visual technologies like classification, segmentation, detection, generation, 3D reconstruction, cross-modal retrieval and so on, through which relevant technologies can provide solutions for different application scenarios. Fashion researches include a variety of applied technologies, which can be summarized as follows:
1.2.1 Image classification
Through image classification technology, clothing such as skirts, short sleeves, hats, shorts and other categories are automatically classified. The corresponding application scenarios of image classification are automatic clothing sorting, content recommendation attribute classification, etc. Classification technology can also be divided into classification based on clothing style, and classification based on clothing attributes.
Classification is based on clothing styles, often targeting categories for specific clothing such as shoes, tops, pants, etc. The pattern of feature extraction network, fully-connected network, and multi-classification loss is often used to recognize clothing classification. Feature extraction networks include the VGG series, Resnet series, and Inception series. The Loss function uses Focal Loss and multi-class cross-entropy Loss, depending on how balanced the dataset is.
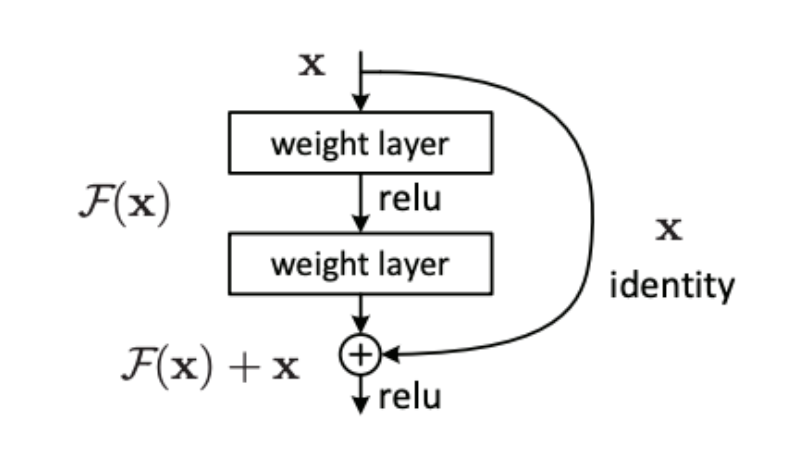
1.2.2 Image segmentation
For a fashion picture, image segmentation technology can distinguish the clothes, pants, and various accessories of the figure in the picture at the pixel level. In the virtual fitting scene, it is often necessary to identify and segment the clothes worn by the experience, so as to replace the virtual clothes more accurately.
Mask R-CNN[3] is often used as the Baseline network structure for image semantic segmentation tasks. Mask R-CNN can be decomposed into Resnet-FPN, RPN, Faster RCNN, and Mask branch. Resnet-FPN performs convolution operations on the input images and extracts features and then obtains feature images of different scales through the FPN layer. RPN selects the most suitable feature map for the candidate region. Finally, the network is divided into two branches, one is the traditional Faster RCNN detection and classification branch; In addition, the Mask prediction task is completed for the unique semantic segmentation branch of the Mask network.
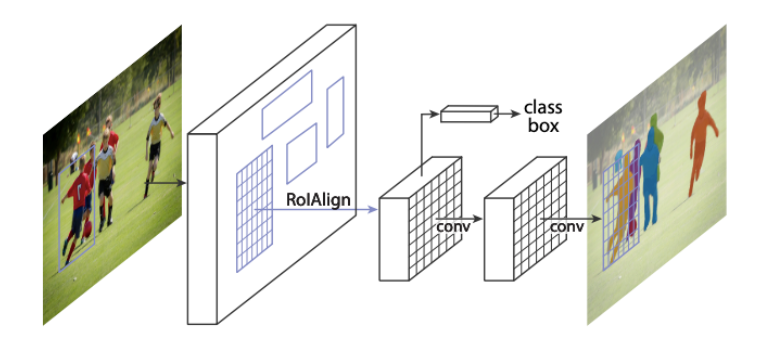
1.2.3 Cross Modal Retrieval And Generation
Cross-modal technology in the Fashion field can be divided into two aspects: generating text descriptions through images, and retrieving relevant clothing pictures from massive data through descriptive text (cross-modal retrieval). Cross-modal techniques often require massive image text descriptions and large-scale training of paired images. The commonly used framework of this kind of task is: by extracting image side features and text side features and optimizing the spatial distance of related modes in the same subspace, the spatial distance of unrelated modal features is gradually approaching, and the irrelevant modal features are gradually estranged.
W2vvpp[4] is a representative work of cross-modal retrieval. By using Bow, Lstm, and W2V at the text end to extract text information and splicing, and then reduce the dimension through the full connection layer, in order to unify with visual features. At the visual end, features were extracted by Resnet and Resnext, and then splicing, and dimensionality were reduced through the full connection layer. Finally, the similarity of the two modal features is calculated to narrow the spatial distance and finally realize the mutual retrieval of different modes. Similarly, Caption is the inverse of retrieval.
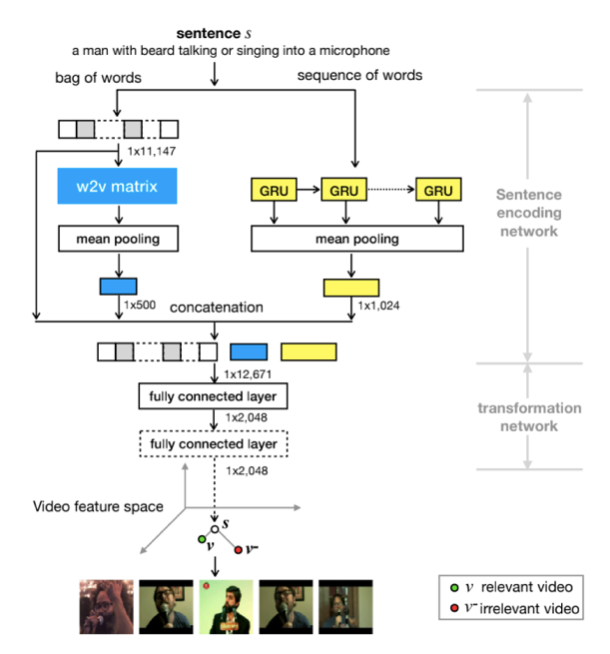
1.2.4 Image Generation
Image generation can be divided into conditional generation and unconditional generation. Conditional generation provides examples of clothing to generate images of similar styles, represented by pix2PIx models. Random disturbance is used as input to generate more diversified images such as DCGAN and ProGAN.

In most generating tasks, antagonism loss is used as loss function, and reconstruction loss is added in some conditional generating tasks. The realization of anti-loss needs a discriminator and a generator as the medium. The generator generates more realistic pictures to mislead the discriminator, and the discriminator tries to distinguish the real picture and the generated picture. When the two reach Nash equilibrium, the realistic generation effect can be achieved. Since the conditional generation task usually has the reference image generated by the target, it is necessary to calculate the L1 loss between the generated image and the reference image pixels to complete the optimization.
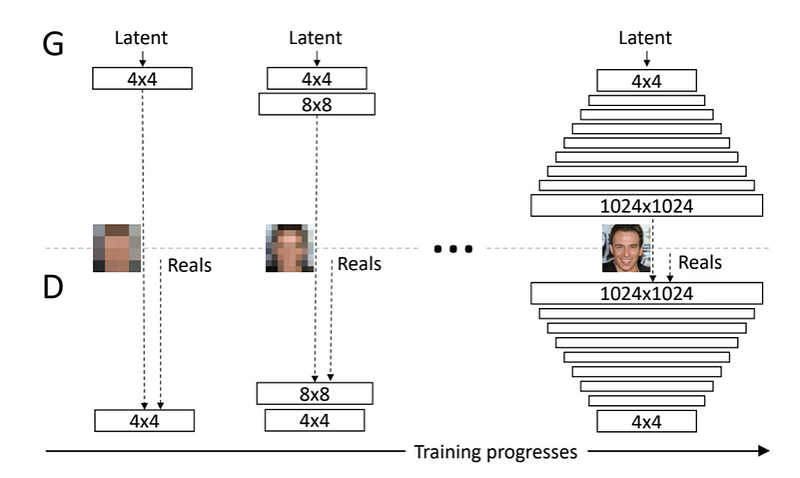
1.2.5 3D reconstruction
In the virtual costume change, the result of the costume change is often presented as a 3D character image. As the general example picture is a flat garment photo in 2d, 3d reconstruction technology is needed to re-model the garment in a 3D scene. 3d reconstruction virtual makeover 1 technology can be divided into two aspects: based on traditional graphics algorithm and based on deep learning algorithm.
Brouet et al. [9] proposed a set of automatic clothing transfer method, which can complete the fitting of clothing between different body types while retaining the clothing style. The method first formalizes the principles used in pattern-grading into a set of geometric constraints, including shape, style, proportion and fit. Then by adjusting the size of the virtual clothing and appropriate deformation to complete the clothing to the target human body transfer. This method ensures that the clothing style does not change after migration. Because the transfer process is carried out in three-dimensional space, the garment model needs to be transformed into two-dimensional pieces for production.
DRAPE[10] proposed a garment deformation method that responds to changes in body shape and posture simultaneously. From a large number of human motion data, they learned the deformation mapping relationship between the garment parameters relative to the human body shape and the rotation of human mesh parts. At the same time, they learned the pose related garment fold generation model, and realized the garment migration between different poses and bodies.
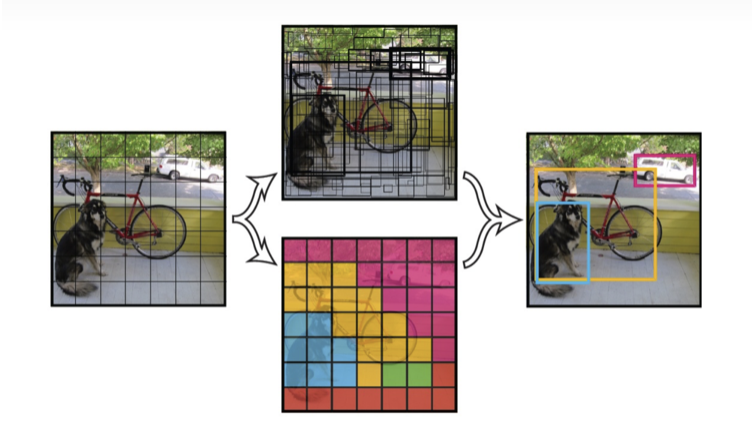
1.2.6 detection
Detection can be divided into target detection and key point detection, and both of them are coordinate points that need to regression clothing according to the picture. It has great technical value in clothing search and recognition.
Yolo[5] is a typical algorithm for target detection. The input first divides an image into a grid, and if the center of an object falls in the grid, the grid is responsible for predicting the object. Each network needs to predict the location information and confidence information of a BBox, and one BBox corresponds to four location information and one confidence information. Confidence represents the confidence of the predicted box containing object and how accurate the box is. The target window can be predicted according to the previous step, and then the target window with low possibility can be removed according to the threshold value. Finally, the NMS can remove the redundant window.
Key point detection techniques can be divided into regression faction and heat map faction. The key point detection of regression faction processing is generally realized by extracting feature network, connecting the whole connection layer and predicting the coordinates of key points. Loss functions are usually MSE or MSE variants. Each channel in the diagram represents a key point of a category. If there are several key points of several categories, there are several channels. The key point position on a channel map is a two-dimensional Gaussian distribution centered around it, and the pixel value of the remaining positions is 0. The result of network prediction is also a thermal diagram. Generally, the most direct way to extract coordinates is to extract the point in a channel whose pixel response is greater than a certain threshold and has the largest response, and the coordinate of this point is the coordinate of the key point of this category.
(TO BE CONTINUED)
Reference List:
- [1] Mohammadi, Seyed Omid, and Ahmad Kalhor. “Smart Fashion: A Review of AI Applications in the Fashion & Apparel Industry.” arXiv preprint arXiv:2111.00905 (2021).
- [2] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- [3] He, Kaiming, et al. “Mask r-cnn.” Proceedings of the IEEE international conference on computer vision. 2017.
- [4] Li, Xirong, et al. “W2vv++ fully deep learning for ad-hoc video search.” Proceedings of the 27th ACM International Conference on Multimedia. 2019.
- [11] Karras, Tero, et al. “Progressive Growing of GANs for Improved Quality, Stability, and Variation.” International Conference on Learning Representations. 2018.
- [9] Brouet, R. , et al. “Design preserving garment transfer.” ACM Transactions on Graphics (TOG) — SIGGRAPH 2012 Conference Proceedings (2012).
- [10] GUAN P, REISS L, HIRSHBERG D A, et al.Drape: Dressing any person[J]. ACM Transactions on Graphics (TOG), 2012,31(4):1–10.
- [5] Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
